6 years ago
Real-Time Data Processing
Real-Time Data Processing Architecture Part. 1
Data is everywhere; and with rapid development and innovations of technology nowadays, it has became more and more important each day. As it has started to have impact on business models and profitability, many businesses rely heavily on data and analytical report when it comes to making decision for the future of the company.
When we talk about ‘Big Data’, we can not ignore the fact on how fast things are changing in the big data world. Applications that are capable to handle few terabytes today, may have to be able to process petabytes of data next year.

Volume, Variety, and Velocity are the three Vs that basically defining the properties and dimensions of big data. Volume refers to the enormous amount of data; variety refers to the many sources and types of data; and velocity refers to the pace at which data is processed. The expansion of all those three characteristics, not just Volume alone, is believed to be what make data processing a big challenge today. The challenge is not to build data sources anymore, but to organize the ‘ocean of data’ efficiently.
Real-time Data Processing—what is it?
A real-time data processing, to quote Techopedia, is the execution of data in a short time period, providing near-instantaneously output. The processing is done as the data is inputted, so it needs a continuous stream of input data in order to provide a continuous output. For that reason, Real-time Data Processing is also called Stream Processing.
While Batch Data Processing stored the data before processing it, Real-time Data Processing involves continual input, process, and output of data. Data must be processed in a small time period, usually within seconds or milliseconds (or near real-time). This allows the organization the ability to take immediate action, since instantaneous result from input data ensures everything is up-to-date.
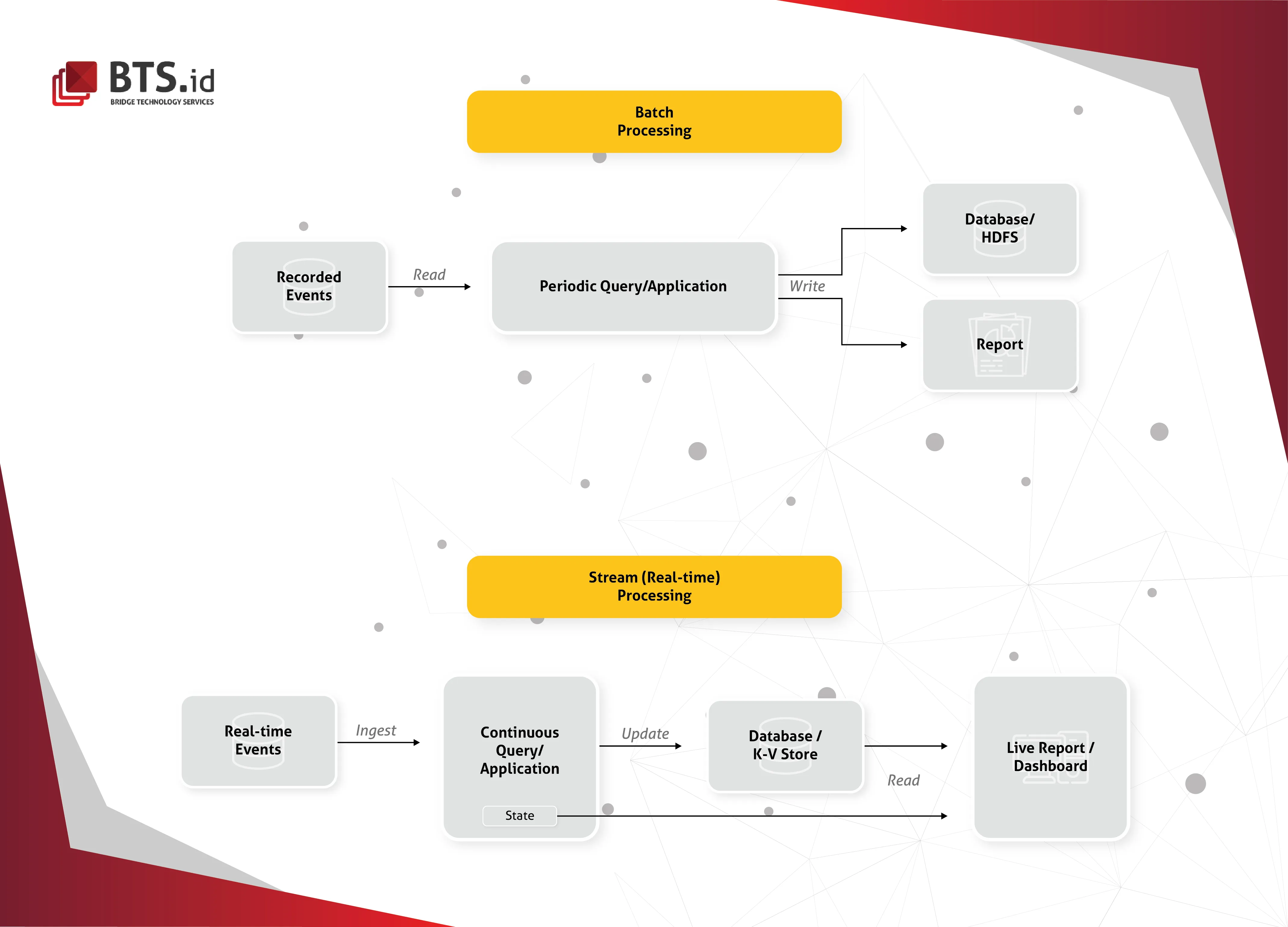
Although still in early adoption, Real-time Data Processing holds many potentials for the future. While most organizations use Batch Data Processing, sometimes there are companies that need to process their data immediately. Nowadays, there are many data sources–such as social networks, IoT devices, customer service, financial service transactions, etc–that broadcast critical information in real-time. Real-time requirements usually have very tight deadlines, often followed with consequences such as degradation of service or worst, a complete failure.
A lot of technologies has been developed to answer those requirements. Regardless of technology we eventually choose to process our data, however, it is important to adopt a good architecture first.
A good real-time data processing architecture has to be scalable. Means, not only it has to answer today’s demand well enough, but also adjust to cater a much bigger one in the future. New machine should be able to be added to the system to scale its capacities and capabilities.
It also has to be fault-tolerant. It needs to support batch and incremental updates, and must be extensible.
Microservice Architecture for Big Data
Microservice Architecture is not originally come from the Big Data world, but is slowly picked up by it.
While there is no formal definition of this architectural style, there are several common aspects exist. A microservice architecture utilizes lightweight, modular, and typically stateless component with well-defined interfaces and contracts.
According to Martin Fowler, the microservice architectural style is “an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API”.
The idea behind this architecture is to built the application as a set of loosely coupled, collaborating services rather than one large code base, unlike monolith architecture. Monolith architecture requires the entire monolith to be rebuilt and deployed when a change made to a small part of the application, which make people frustrated, hence the development of microservice architecture.
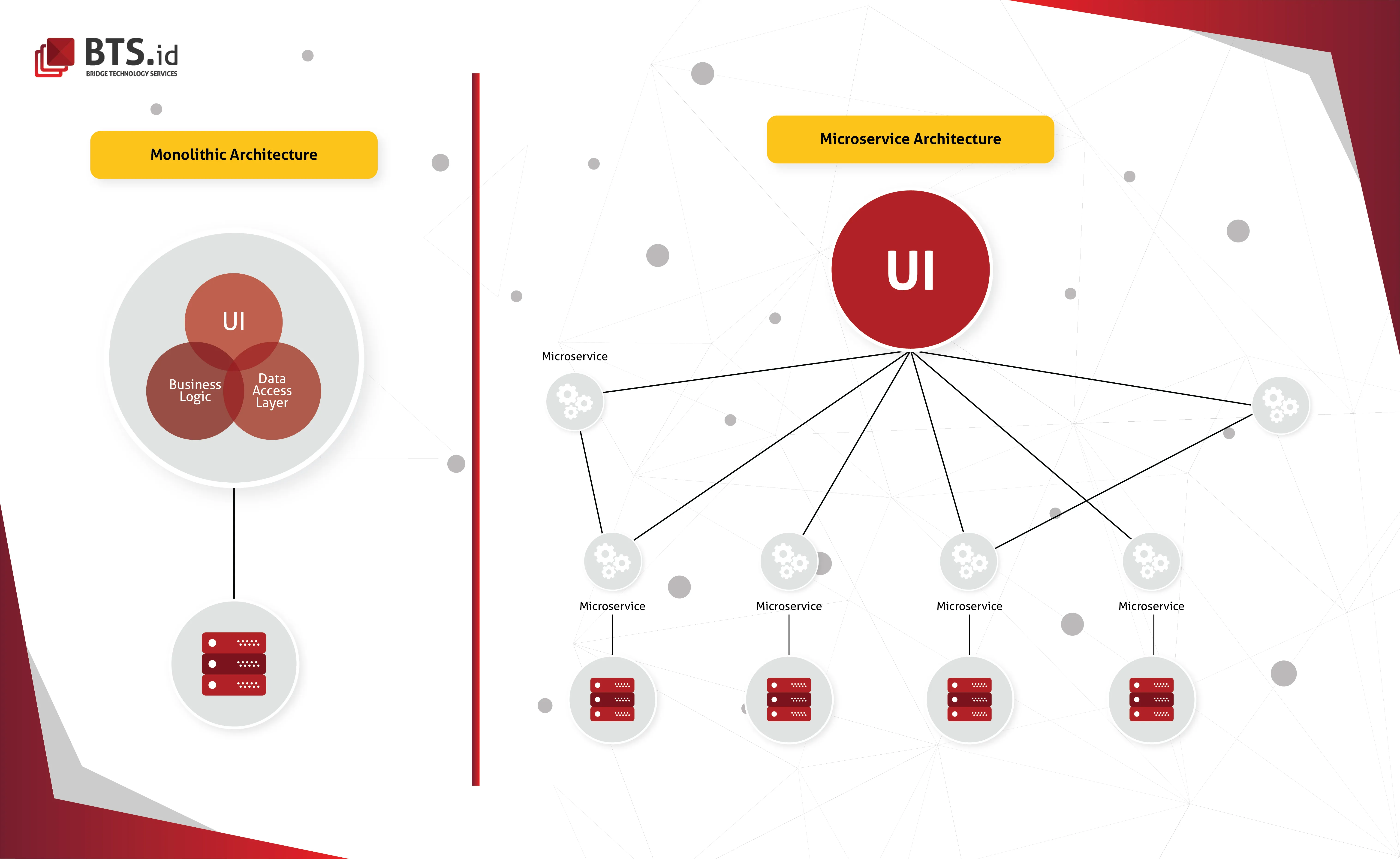
Microservice architecture affect the connection between application and database significantly. Instead of sharing a single database schema with another services, each service posseses its own database schema.
Since monolithic architecture puts all of its functionality into a single process and replicating requires replication of the whole application, which has limitations, a microservice architecture could facilitates a cost-effective scaling.
If you plan to develop a server-side enterprise application that must support a variety of different clients including desktop browsers, mobile browsers, and native mobile applications; expose API tor 3rd party to consume; or integrate with other applications through either web services or a message broker, this architecture might be the answer to solve the question of the right deployment architecture.
A lot of large scale websites including Netflix, Amazon, eBay have proceeded to adopt microservice architecture over the previously-used monolithic architecture. Perhaps because many of its advantages, such as it’s scalable, secure, and reliable. Each service stands on its own, thus it’s easier to maintain and developers can develop each service without interfering another services.
Read Next: Real-Time Data Processing Architecture Part. 2
Build software for your business with the best practice and latest technology with BTS.id (Bridge Technology Services).
![]()
Contact us:
Telp : (+62 22) 6614726
Email : info@bts.id
HIT US UP
BRIDGE TECHNOLOGY SERVICES
In the previous article, we have already talked about big data, real-time data processing, and microservice architecture for big data. In this article, we will dig into the messaging system deeper, and see how messaging queue makes our life easier for certain scenarios in microservices architecture.
Read First: Real-Time Data Processing Architecture Part. 1
Message Queuing with Message Brokers
In a more complex scheme when your application is not only taking orders from customers, but also need to verifies inventory and ships them, a message queuing or message brokers is needed to facilitate the communication between services. A message queuing allows applications to send messages to each other by providing an asynchronous communications protocol that puts a message onto a queue where immediate response to continue processing is not required.
The basic architecture of a message queue is simple. Producers, which are client applications will create messages and deliver them to the message queue. Later, an other application called consumers will connect to the queue and get the messages to be processed. While waiting till consumers retrieve them, messages placed onto the queue will be stored.
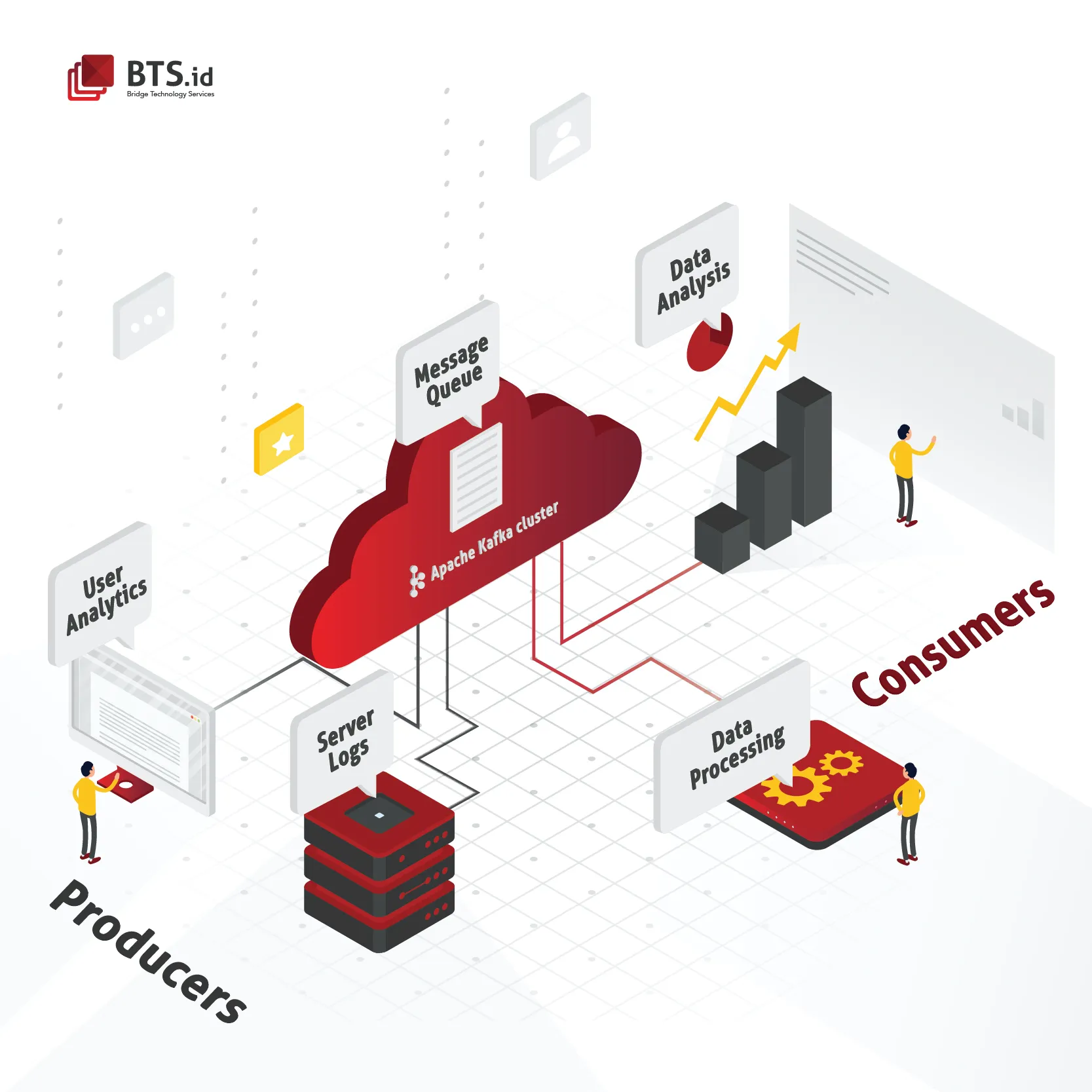
For example, let’s imagine you are developing an application for ticket-booking. When users book a ticket, booking service will take the request, process the booking data, and give feedback that is usually a booking code complete with its details, a scheme that is manageable using monolithic architecture. But in a more complex scheme where users book more than 1 tickets and demand additional features such as send booking details to email or send push notifications to messages, users will have to wait until all the processes are done, with no guarantee that it will be succeed.
To solve the problem above, an additional service called a message broker that allow data to be exchanged in a simple and reliable manner is needed. A message broker like Apache Kafka is responsible for gathering, routing, and distributing messages from senders to the right receiver. And it provides better ordering guarantees than a traditional message brokers.
According to Wikipedia, a message broker “translates a message from the formal messaging protocol of the sender to the formal messaging protocol of the receiver.”
Apache Kafka
![]()
Apache Kafka is a message broker that is often used in real-time streaming data architecture to provide real-time analytic and is often used for real-time streams of data, to collect big data, or to do real-time analysis. According to co-creator Jay Kreps, it is built to be fault-tolerant, high throughput, horizontally scalable, and allows geographically distributing data streams and stream processing applications.
It is not only popular, but also rising rapidly. It is used by a lot of companies who handle a lot of data such as Linkedin, Twitter, Square, Uber, Paypal, Cisco, eBay, Pinterest, and Netflix. Apache Kafka was developed around 2010 at Linkedin to solve the problem of integrating huge amounts of data from their website and infrastructure into a Lambda architecture that harnessed Hadoop and real-time processing system.
At that time, there weren’t any solutions for this type of ingress for real-time applications, and traditional message brokers did not satisfy Linkedin needs. They were too heavy and slow, and were not designed for real-time use case as well.
The Engineering team at Linkedin then developed a scalable and fault-tolerant messaging system without any of the unnecessary parts, which has quickly transformed into a full-fledged event streaming platform that is Apache Kafka.
Why Apache Kafka is so Popular?
Apache Kafka gains immense popularity for its simplicity and compatibility. It is easy to set up and use. It is fast, scalable, durable, and fault-tolerant. It can be used with a wide range of system. And it also has a great performance as it works well with systems that have data streams to process and enables those systems to aggregate, transform, and load into other stores.
Unlike other message brokers, Kafka combines the function of messaging, storage, and processing, makes it a powerful event streaming platform capable of handling trillions of messages a day. Kafka can both store and process historical data from the past and for real time work, therefore suitable for developing streaming applications as well as for streaming data pipelines.
How Apache Kafka Works
Storing 1000 data from many data sources such as JSON, XML, etc to one database might be okay, but the question that often arises in today’s world where big data is considered important, what if there is one million data need to be stored? And what if each data source has ten million data?
How long will it take till everything stored without creating data burst?
Apache Kafka works by combining Queuing and Publish-subscribe which are the two main patterns of messaging. Each with its own pros and cons–Queuing provides the opportunity to easily scale the processing, but aren’t multi-subscriber, while Publish-subscribe gives the possibility to broadcast data to multiple consumer groups, but it is difficult to scale–but with Apache Kafka, benefits from both data processing patterns can be obtained.
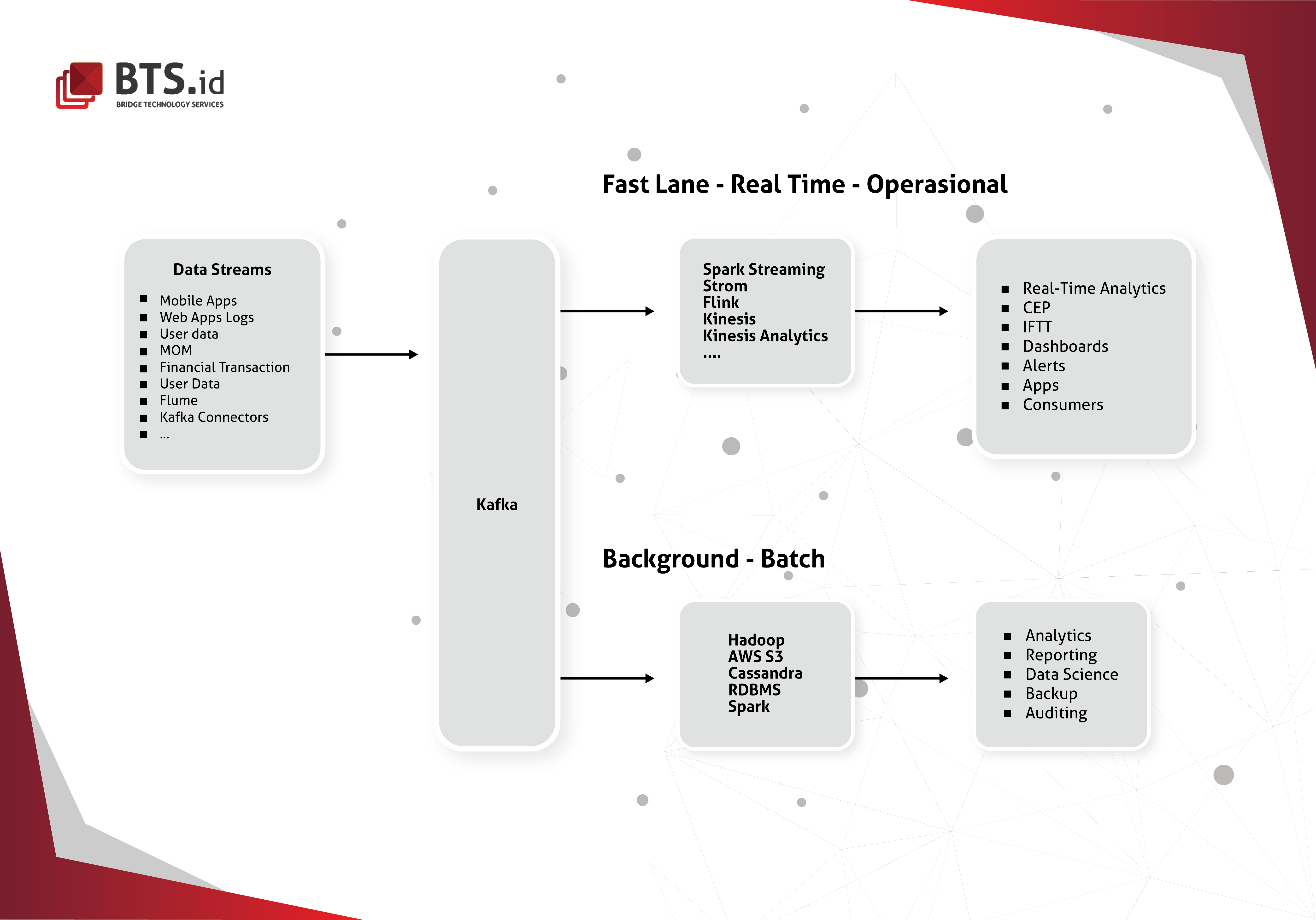
Apache Kafka also works as a middle layer to decouple your real-time data pipelines. It acts as a middleware to prevent database being directly bombarded. Messages will be sent to the middle layer and pulled by microservice as fast as possible before being inserted to the database.
As shown in the picture above, data source is being sent to Redis. From there, some are directed to notification, and some to Kafka. Kafka then process the data into a more organized form, before storing it in Hadoop Distributed File System (HDFS)
Kafka can be used to feed fast lane systems and it can be used to feed events to CEP (Complex Event Streaming System) and IoT/IFTTT-style automation system. It is also used to stream data for batch data analysis. It feeds Hadoop and streams data for into your Big Data platform for future data analysis.
Build software for your business with the best practice and latest technology with BTS.id (Bridge Technology Services).
![]()
Contact us:
Telp : (+62 22) 6614726
Email : info@bts.id
MORE ARTICLE
BRIDGE TECHNOLOGY SERVICES


